Explosions in the Sky - A (not so very) Deep Dive into the World of Explosions FP16 Space
==================
Preface
I’m going to start blogging a bit more on day-to-day random issues that aren’t NDA’d topics, sort of the slog/grind of the day to day in the life of a scientist in the AI space.
Float16 explosions in inference and not training?
stream of consciousness: wut? why? this inference code works in float32 for 100% of the inputs. however, in float16 no problems for like 99% of inputs. but for 1% of inputs, it explodes/returns nulls?
very weird.
let’s rewrite our forward forward function of this embedder to find out what in the world is happening.
Rewriting our forward function to find out what in the friday night lights is happening
we’ll print/log each step and save to a np/pickle file the weights before and after given layers/activations.
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
output_all_encoded_layers: Optional[bool] = True,
subset_mask: Optional[torch.Tensor] = None,
position_encodings: Optional[torch.Tensor] = None,
) -> List[torch.Tensor]:
from einops import rearrange
from infinity_emb.transformer.monarch.mm.hyena_utils import fftconv_ref
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
import opt_einsum as oe
contract = oe.contract
def check_nan(tensor, location):
if torch.isnan(tensor).any():
nan_count = torch.isnan(tensor).sum().item()
print(f"NaN detected in {location}: {nan_count} NaN values")
return True
return False
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(
dtype=next(self.parameters()).dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
attention_mask_bool = attention_mask.bool()
batch, seqlen = hidden_states.shape[:2]
# Unpad inputs and mask. It will remove tokens that are padded.
# Assume ntokens is total number of tokens (padded and non-padded)
# and ntokens_unpad is total number of non-padded tokens.
# Then unpadding performs the following compression of the inputs:
# hidden_states[ntokens,hidden] -> hidden_states[ntokens_unpad,hidden]
if not self.monarch_mixer_sequence_mixing:
hidden_states, indices, cu_seqlens, _ = bert_padding_module.unpad_input(
hidden_states, attention_mask_bool)
else:
cu_seqlens = None
indices = None
# Add alibi matrix to extended_attention_mask
if not self.monarch_mixer_sequence_mixing:
if self._current_alibi_size < seqlen:
# Rebuild the alibi tensor when needed
warnings.warn(
f'Increasing alibi size from {self._current_alibi_size} to {seqlen}'
)
self.rebuild_alibi_tensor(size=seqlen, device=hidden_states.device)
elif self.alibi.device != hidden_states.device:
# Device catch-up
self.alibi = self.alibi.to(hidden_states.device)
alibi_bias = self.alibi[:, :, :seqlen, :seqlen]
attn_bias = extended_attention_mask[:, :, :seqlen, :seqlen]
alibi_attn_mask = attn_bias + alibi_bias
else:
alibi_attn_mask = None
all_encoder_layers = []
if self.monarch_mixer_sequence_mixing:
for layer_idx, layer_module in enumerate(self.layer):
# u is B L H
print(f"starting: Layer {layer_idx} {layer_module}")
check_nan(hidden_states, f"Layer {layer_idx} input")
u = hidden_states
if layer_module.attention.hyena_training_additions:
u = layer_module.attention.layernorm(u)
check_nan(u, f"Layer {layer_idx} u = layer_module.attention.layernorm(u)")
L = u.size(-2)
u_orig = u
u = layer_module.attention.in_linear(u)
check_nan(u, f"Layer {layer_idx} u = self.in_linear(u)")
u = rearrange(u, "b l d -> b d l")
check_nan(u, f"Layer {layer_idx} u = rearrange(u, 'b l d -> b d l')")
# short filter
uc = layer_module.attention.short_filter(u)[..., :L]
check_nan(uc, f"Layer {layer_idx} layer_module.attention.short_filter(u)[..., :L]")
x1, x2, v = uc.split(layer_module.attention.d_model, dim=1)
check_nan(x1, f"Layer {layer_idx} x1")
check_nan(x2, f"Layer {layer_idx} x2")
check_nan(v, f"Layer {layer_idx} v")
v = v * x1
check_nan(v, f"Layer {layer_idx} v = v * x1")
if layer_module.attention.hyena_training_additions:
v = layer_module.attention.drop(v)
check_nan(v, f"Layer {layer_idx} v = layer_module.attention.drop(v)")
k = layer_module.attention.filter_fn.filter(L, device=u.device)
check_nan(k, f"Layer {layer_idx} k = layer_module.attention.filter_fn.filter(L, device=u.device)")
k = rearrange(k, "c l d -> c d l")[0] # `c` is always 1 by default
check_nan(k, f"Layer {layer_idx} k = rearrange(k, 'c l d -> c d l')[0] # `c` is always 1 by default")
if layer_module.attention.bidirectional:
k_rev = layer_module.attention.filter_fn.filter_rev(L, device=u.device)
check_nan(k_rev, f"Layer {layer_idx} k_rev = layer_module.attention.filter_fn.filter_rev(L, device=u.device)")
k_rev = rearrange(k_rev, "c l d -> c d l")[0] # `c` is always 1 by default
check_nan(k_rev, f"Layer {layer_idx} k = rearrange(k, 'c l d -> c d l')[0] # `c` is always 1 by default")
else:
k_rev = None
y = layer_module.attention.filter_fn(v, L, k_fwd=k, k_rev=k_rev, bias= layer_module.attention.filter_fn.bias[None, :, None])
check_nan(y, f"Layer {layer_idx} y = layer_module.attention.filter_fn(v, L, k_fwd=k, k_rev=k_rev, bias= layer_module.attention.filter_fn.bias[None, :, None])")
if layer_module.attention.residual_long_conv:
k2 = layer_module.attention.filter_fn2.filter(L, device=u.device)
check_nan(k2, f"Layer {layer_idx} k2 = layer_module.attention.filter_fn2.filter(L, device=u.device)")
k2 = rearrange(k2, "c l d -> c d l")[0]
check_nan(k2, f"Layer {layer_idx} rearrange(k2, 'c l d -> c d l')[0]")
if layer_module.attention.bidirectional:
k2_rev = layer_module.attention.filter_fn2.filter_rev(L, device=u.device)
check_nan(k2_rev, f"Layer {layer_idx} k2_rev = layer_module.attention.filter_fn2.filter_rev(L, device=u.device)")
k2_rev = rearrange(k2_rev, "c l d -> c d l")[0] # `c` is always 1 by default
check_nan(k2_rev, f"Layer {layer_idx} rearrange(k2_rev, 'c l d -> c d l')[0]")
else:
k2_rev = None
yu = layer_module.attention.filter_fn2(u_orig.transpose(-1, -2), L, k_fwd=k2, k_rev=k2_rev, bias= layer_module.attention.filter_fn2.bias[None, :, None])
check_nan(yu, f"Layer {layer_idx} yu = layer_module.attention.filter_fn2(u_orig.transpose(-1, -2), L, k_fwd=k2, k_rev=k2_rev, bias= layer_module.attention.filter_fn2.bias[None, :, None])")
# post gating
y = y * x2
check_nan(y, f"Layer {layer_idx} y = y * x2")
if layer_module.attention.residual_long_conv:
y = y + yu
check_nan(y, f"Layer {layer_idx} y = y + yu")
y = y.transpose(-1, -2)
check_nan(y, f"Layer {layer_idx} y = y.transpose(-1, -2)")
if layer_module.attention.hyena_training_additions:
y = layer_module.attention.drop(layer_module.attention.act(y))
check_nan(y, f"Layer {layer_idx} y = layer_module.attention.drop(layer_module.attention.act(y))")
# for debugging
# print("y.shape:", y.shape)
# print("layer_module.attention.out_linear.weight.shape:", layer_module.attention.out_linear.weight.shape)
# print("layer_module.attention.out_linear.bias.shape:", layer_module.attention.out_linear.bias.shape)
y = layer_module.attention.out_linear(y)
check_nan(y, f"Layer {layer_idx} y = layer_module.out_linear(y)")
#hidden_states = layer_module.mlp(y)
#check_nan(y, f"Layer {layer_idx} hidden_states = layer_module.mlp(y)")
hidden_states = y
residual_connection = hidden_states
# compute the activation
hidden_states = layer_module.mlp.gated_layers(hidden_states)
check_nan(hidden_states, f"Layer {layer_idx} hidden_states = layer_module.mlp.gated_layers(hidden_states)")
print(f"Layer {layer_idx} after gated_layers stats:")
print(f"Mean: {hidden_states.mean().item()}")
print(f"Max abs: {hidden_states.abs().max().item()}")
print(f"% > 5: {(hidden_states.abs() > 5).float().mean().item() * 100}%")
if layer_module.mlp.is_padded:
gated = hidden_states[:, :, :layer_module.mlp.config.intermediate_size]
check_nan(gated, f"Layer {layer_idx} gated = hidden_states[:, :, :layer_module.mlp.config.intermediate_size]")
non_gated = hidden_states[:, :, layer_module.mlp.config.intermediate_size:]
check_nan(non_gated, f"Layer {layer_idx} non_gated = hidden_states[:, :, layer_module.mlp.config.intermediate_size:]")
else:
gated = hidden_states[:, :layer_module.mlp.config.intermediate_size]
check_nan(gated, f"Layer {layer_idx} gated = hidden_states[:, :layer_module.mlp.config.intermediate_size]")
non_gated = hidden_states[:, layer_module.mlp.config.intermediate_size:]
check_nan(non_gated, f"Layer {layer_idx} non_gated = hidden_states[:, layer_module.mlp.config.intermediate_size:]")
hidden_states = layer_module.mlp.act(gated) * non_gated
hidden_states = torch.clamp(hidden_states, min=-10000.0, max=10000.0)
check_nan(hidden_states, f"Layer {layer_idx} hidden_states = layer_module.mlp.act(gated) * non_gated")
print(f"Layer {layer_idx} after activation and gating stats:")
print(f"Mean: {hidden_states.mean().item()}")
print(f"Max abs: {hidden_states.abs().max().item()}")
print(f"% > 5: {(hidden_states.abs() > 5).float().mean().item() * 100}%")
hidden_states = layer_module.mlp.dropout(hidden_states)
check_nan(hidden_states, f"Layer {layer_idx} hidden_states = layer_module.mlp.dropout(hidden_states)")
# multiply by the second matrix
hidden_states = layer_module.mlp.wo(hidden_states)
check_nan(hidden_states, f"Layer {layer_idx} hidden_states = layer_module.mlp.wo(hidden_states)")
print(f"Layer {layer_idx} after wo stats:")
print(f"Mean: {hidden_states.mean().item()}")
print(f"Max abs: {hidden_states.abs().max().item()}")
print(f"% > 5: {(hidden_states.abs() > 5).float().mean().item() * 100}%")
# add the residual connection and post-LN
combine = hidden_states + residual_connection
print(f"Layer {layer_idx} combine stats:")
print(f"Mean: {combine.mean().item()}")
print(f"Std: {combine.std().item()}")
print(f"Max: {combine.abs().max().item()}")
print(f"% of values > 5: {(combine.abs() > 5).float().mean().item() * 100}%")
check_nan(combine, f"Layer {layer_idx} hidden_states + residual_connection")
hidden_states = layer_module.mlp.layernorm(combine)
check_nan(hidden_states, f"Layer {layer_idx} hidden_states = layer_module.mlp.layernorm(combine)")
if position_encodings is not None:
hidden_states = hidden_states + position_encodings
check_nan(hidden_states, f"Layer {layer_idx} after position encoding")
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
if subset_mask is not None:
hidden_states = hidden_states[subset_mask]
check_nan(hidden_states, f"After subset mask")
else:
if subset_mask is None:
for layer_module in self.layer:
hidden_states = layer_module(hidden_states,
cu_seqlens,
seqlen,
None,
indices,
attn_mask=attention_mask,
bias=alibi_attn_mask
)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
# Pad inputs and mask. It will insert back zero-padded tokens.
# Assume ntokens is total number of tokens (padded and non-padded)
# and ntokens_unpad is total number of non-padded tokens.
# Then padding performs the following de-compression:
# hidden_states[ntokens_unpad,hidden] -> hidden_states[ntokens,hidden]
hidden_states = bert_padding_module.pad_input(
hidden_states, indices, batch, seqlen
)
else:
for i in range(len(self.layer) - 1):
layer_module = self.layer[i]
hidden_states = layer_module(hidden_states,
cu_seqlens,
seqlen,
None,
indices,
attn_mask=attention_mask,
bias=alibi_attn_mask)
if output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
subset_idx = torch.nonzero(subset_mask[attention_mask_bool],
as_tuple=False).flatten()
hidden_states = self.layer[-1](hidden_states,
cu_seqlens,
seqlen,
subset_idx=subset_idx,
indices=indices,
attn_mask=attention_mask,
bias=alibi_attn_mask)
if not output_all_encoded_layers:
all_encoder_layers.append(hidden_states)
return all_encoder_layers
And because one specifc operation is abstracted, we’ll add a debug/pickler for it as well.
# Adapted from https://github.com/HazyResearch/fly/tree/master/src/models/layers
import numpy as np
import torch
from einops import rearrange
def blockdiag_weight_to_dense_weight(weight):
"""
Argumments:
weight: (nblocks, out / nblocks, in / blocks)
Return:
dense_weight: (out / in)
"""
return torch.block_diag(*torch.unbind(weight, dim=0))
def blockdiag_multiply_reference(x, weight):
"""
This implementation is slow but more likely to be correct.
Arguments:
x: (..., n)
weight: (nblocks, q, n / nblocks)
Outputs:
out: (..., nblocks * q)
"""
n = x.shape[-1]
nblocks, q, p = weight.shape
assert nblocks * p == n
x_reshaped = rearrange(x, "... (nblocks p) -> ... nblocks p", nblocks=nblocks)
return rearrange(
torch.einsum("...kp, kqp -> ...kq", x_reshaped, weight),
"... nblocks q -> ... (nblocks q)",
)
class BlockdiagMultiply(torch.autograd.Function):
"""This is a faster implementation, with careful memory copies for the fastest
bmm performance.
The backward pass is also written manually with careful memory copies.
Arguments:
x: (..., n)
weight: (nblocks, q, n / nblocks)
Outputs:
out: (..., nblocks * q)
"""
@staticmethod
@torch.cuda.amp.custom_fwd(cast_inputs=torch.bfloat16)
def forward(ctx, x, weight):
ctx.save_for_backward(x, weight)
batch_shape, n = x.shape[:-1], x.shape[-1]
batch_dim = np.prod(batch_shape)
nblocks, q, p = weight.shape
assert nblocks * p == n
x_reshaped = x.reshape(batch_dim, nblocks, p).transpose(0, 1)
out = torch.empty(
batch_dim, nblocks, q, device=x.device, dtype=x.dtype
).transpose(0, 1)
out = torch.bmm(x_reshaped, weight.transpose(-1, -2), out=out).transpose(0, 1)
# Create directory if it doesn't exist
viz_dir = 'block_multiple_viz'
os.makedirs(viz_dir, exist_ok=True)
# Get next file number
existing_files = os.listdir(viz_dir)
numbers = [int(f.split('_')[-1].split('.')[0]) for f in existing_files if f.endswith('.pkl')]
next_num = max(numbers + [-1]) + 1
# Save tensors
x_path = os.path.join(viz_dir, f'x_reshaped_{next_num:04d}.pkl')
out_path = os.path.join(viz_dir, f'out_{next_num:04d}.pkl')
with open(x_path, 'wb') as f:
pickle.dump(x_reshaped.detach().cpu().numpy(), f)
with open(out_path, 'wb') as f:
pickle.dump(out.detach().cpu().numpy(), f)
# clamp to avoid overflow + see explosions in later layers
out = torch.clamp(out, min=-10000.0, max=10000.0)
return out.reshape(*batch_shape, nblocks * q)
# not used now..
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout):
x, weight = ctx.saved_tensors
batch_shape, n = x.shape[:-1], x.shape[-1]
batch_dim = np.prod(batch_shape)
nblocks, q, p = weight.shape
assert nblocks * p == n
dx, dweight = None, None
dout_reshaped = dout.reshape(batch_dim, nblocks, q).transpose(0, 1)
if ctx.needs_input_grad[0]:
dx = torch.empty(batch_dim, nblocks, p, device=x.device, dtype=x.dtype)
dx = (
torch.bmm(dout_reshaped, weight.conj(), out=dx.transpose(0, 1))
.transpose(0, 1)
.reshape(*batch_shape, n)
)
dx = torch.clamp(dx, min=-10000.0, max=10000.0)
if ctx.needs_input_grad[1]:
x_reshaped = x.reshape(batch_dim, nblocks, p).transpose(0, 1)
dweight = torch.bmm(dout_reshaped.transpose(-1, -2), x_reshaped.conj())
dweight = torch.clamp(dweight, min=-10000.0, max=10000.0)
return dx, dweight
blockdiag_multiply = BlockdiagMultiply.apply
Cool, that gave us the results we’re looking for.
specifically, a single layer was causing explosions, shooting values up to > 65k while mean/std were 0/10 or something like that.
what in the world.
let’s try to see what’s going on in tsne space.
load outputs + slap a tsne on it + viz
x_reshaped = pickle.load(open('x_reshaped_0009.pkl','rb'))
out = pickle.load(open('out_0009.pkl','rb'))
x_2d = x_reshaped.transpose(1, 0, 2).reshape(-1, x_reshaped.shape[-1]) # (batch_dim * nblocks, p)
out_2d = out.transpose(1, 0, 2).reshape(-1, out.shape[-1]) # (batch_dim * nblocks, q)
# TSNE reduction
tsne = TSNE(n_components=3, random_state=42)
x_tsne = tsne.fit_transform(x_2d)
out_tsne = tsne.fit_transform(out_2d)
# Create mask for clamped values
clamped_mask = np.abs(out_2d).max(axis=1) >= 10000
viz
# Create subplot figure
fig = make_subplots(
rows=1, cols=2,
specs=[[{'type': 'scatter3d'}, {'type': 'scatter3d'}]],
subplot_titles=('Input Values (TSNE)', 'Output Values (TSNE)')
)
# Add traces for input
fig.add_trace(
go.Scatter3d(
x=x_tsne[~clamped_mask, 0],
y=x_tsne[~clamped_mask, 1],
z=x_tsne[~clamped_mask, 2],
mode='markers',
marker=dict(
size=5,
color=np.abs(x_2d).mean(axis=1),
colorscale='Viridis',
showscale=True
),
name='Input'
),
row=1, col=1
)
# Add traces for input
fig.add_trace(
go.Scatter3d(
x=x_tsne[clamped_mask, 0],
y=x_tsne[clamped_mask, 1],
z=x_tsne[clamped_mask, 2],
mode='markers',
marker=dict(
size=8,
color='red',
),
name='Input'
),
row=1, col=1
)
# Add normal output values
fig.add_trace(
go.Scatter3d(
x=out_tsne[~clamped_mask, 0],
y=out_tsne[~clamped_mask, 1],
z=out_tsne[~clamped_mask, 2],
mode='markers',
marker=dict(
size=5,
color=np.abs(out_2d[~clamped_mask]).mean(axis=1),
colorscale='Viridis',
showscale=True
),
name='Normal Output'
),
row=1, col=2
)
# Add clamped output values in red
fig.add_trace(
go.Scatter3d(
x=out_tsne[clamped_mask, 0],
y=out_tsne[clamped_mask, 1],
z=out_tsne[clamped_mask, 2],
mode='markers',
marker=dict(
size=8,
color='red',
),
name='Clamped Output'
),
row=1, col=2
)
fig.update_layout(
height=800,
width=1600,
title_text="TSNE Visualization with Highlighted Clamped Values",
showlegend=True
)
fig.show()
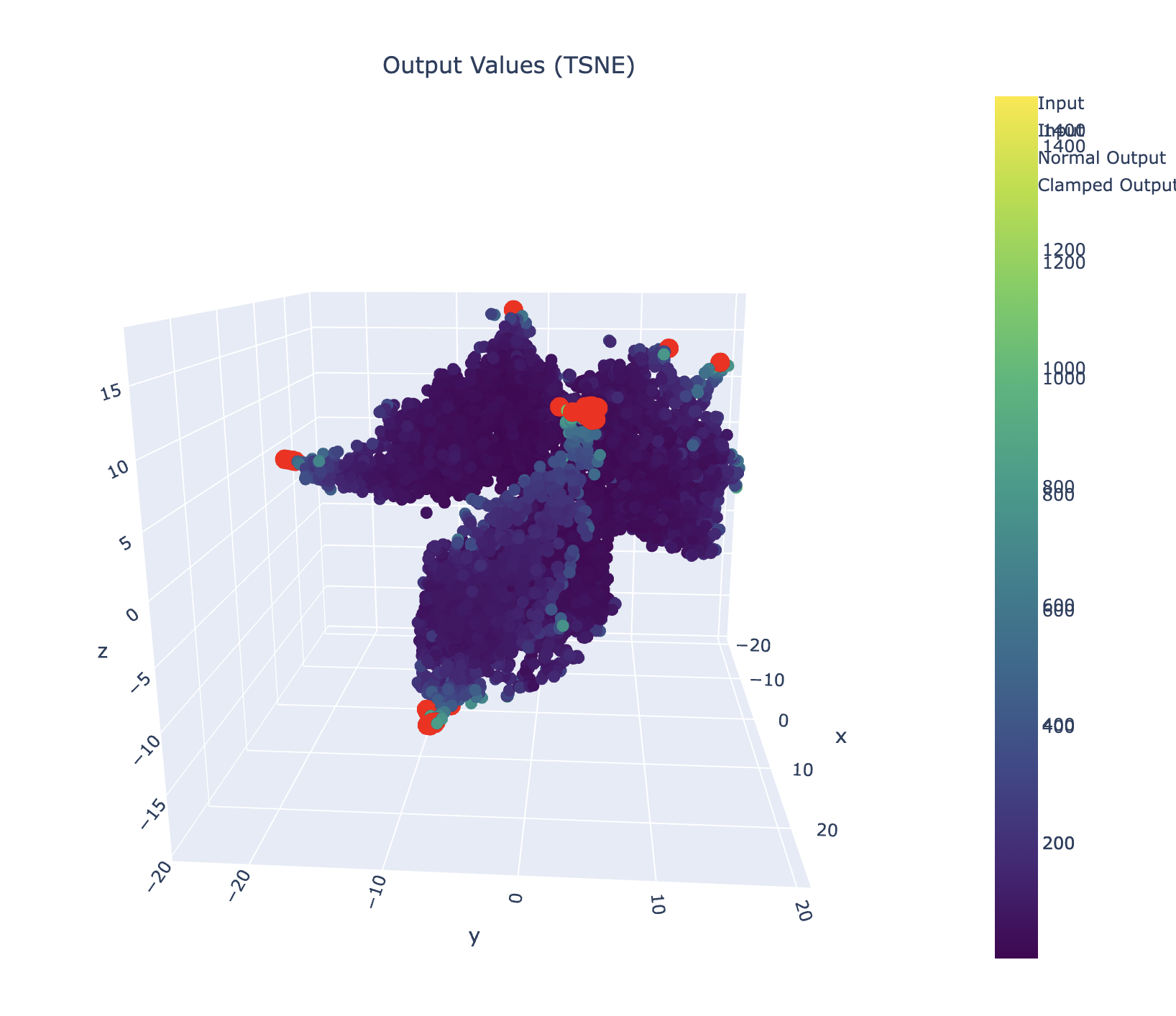
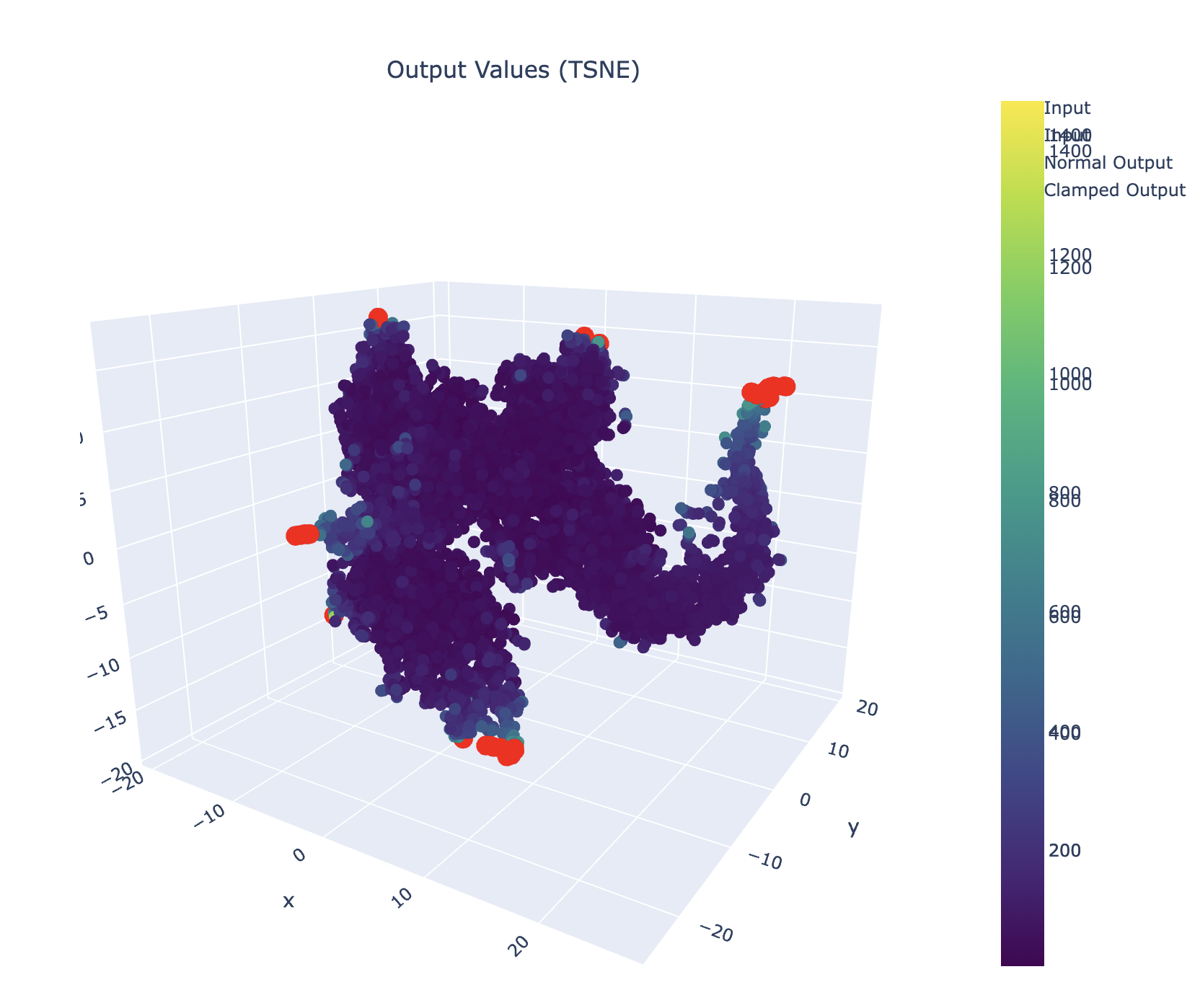
what tokens cause this nasty bastard?
hacky pseudo code
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokens = tokenizer.encode(text, add_special_tokens=True)
problematic_tokens = []
for i, token in enumerate(tokens):
test_text = tokenizer.decode([token])
data = {
"model": "super-duper-custom-model",
"input": test_text
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if not response.ok:
problematic_tokens.append({
'token_id': token,
'token_text': test_text,
'position': i
})
print(f"Found problematic token at position {i}: {test_text}")
return problematic_tokens
results = test_individual_tokens(text2)
print(f"\nTotal problematic tokens found: {len(results)}")
well that doesn’t make too much sense.
“owner”? the word “`owner” causes the problem but not, specifically, “owners”? weird. either way, we can fix this problem by clamping after the bmm operator and checking to make sure the clamp doesn’t effect similarity too hard. (test not pictured, it fixes it, casues no issues, all is right in the world)
fin. that’s a wrap. welcome to the world of the odd. debugging precision issues in 2024.
join me next week for another deep dive in to the world of the odd.