Whiskey Embeddings
==================
A little background:
Recently my friends and I started a whisky club. Every 3 weeks, we get together, bring a few bottles of whiskey/beer and just hangout, talk shop, and ultimately, praise the nectar of the gods. For the beer guys, or really anyone in general, buying a bomber or a six pack is pretty easy. You can drop 15 bucks on a bomber and not feel completely guilty if you made a bad purchase. However, if you spend 90 bucks on bottle of whiskey and you absolutely hate it, you could have easily just spent that on 6 different bombers. So when you’re new to whiskey, or are wanting to take the plunge and buy your first bottle, it’s incredibly easy to get caught up in some hacky marketing telling you about Rare Casks or about the juice some functional alcoholic who wasn’t as good as Dean Martin used to drink.
Back to barriers of entry; I wanted to make something so that the less-experienced guys, or really anyone in the club, could query whiskies at the store and figure out if the flavors would ignite their interest. The goal would be to not waste money on an absolute dud, but instead find something that you actually might like. That was the primary goal. We found the second benefit born out of our own poor ability to describe a whiskey.
What is that flavor? I can’t put my finger on it? It’s sweet. Candy-ish, almost. What the hell is that?.
Pop open this beast on localhost -> query the whiskey -> check the taste -> maraschino fuckin’ cherries. Bam. That’s exactly it.
Given that this model passes a lot of eye tests for me, I use this little helper so that I can make a decision on a bottle if I’m really in the mood for something specific. You might be thinking - Really? Another fucking recommender system?… If that’s you, then I like you, we’d probably be friends. You have an open invite to whiskey-club.
Table of Contents
-
If you’re familiar with whiskey, but unfamiliar with machine learning
-
If you’re familiar with machine learning, but unfamiliar with whiskey
If you’re familiar with whiskey, but unfamiliar with machine learning
This particular model uses word-embeddings. Word embeddings have a long history in machine learning. All starting with Hinton in 1986, Geoffrey Hinton. Learning Distributed Representations of Concepts. Proceedings of the Eigth Annual Conference of the Cognitive Science Society. Amherst, Mass. 1:12, 1986 all the way to the seminal word embedding paper from Mikolov et al. T. Mikolov, K. Chen, G. Corrado, J. Dean. Efficient Estimation of Word Representations in Vector Space. Word embeddings can be thought of as the distributed representation of words that capture a large number of precise syntactic and semantic word-relationships. (Mikolov et al - arXiv:1310.4546). At a very high level, when words are embedded, we can start to use analogous reasoning to gauge the effectiveness of various models. Here is what has become the seminal example to define this type of reasoning:
Q: man is to woman as king is to what?
The algorithm then returns:Queen.
Stealing from the ever amazing Stitchfix Multithreaded blog, here is a small gif that encapsulates this idea to a T.
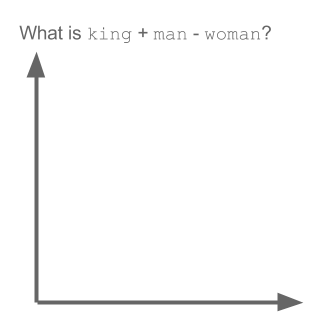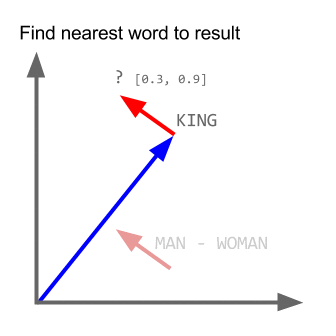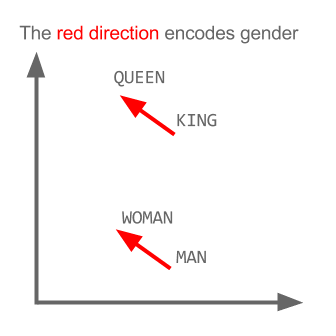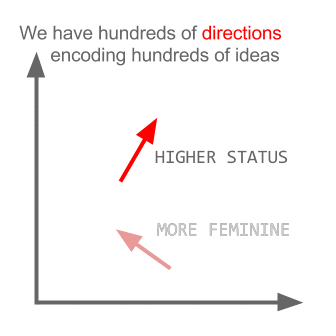
In whisky terms, peat is to smoke as PX is to raisin; where the the difference (smoke - peat) encodes the source from which the flavor came. The most important thing to keep in mind is that none of this is done by explicitly stating to the algorithm ‘During the kilning, barley is dried over a peat fire, and that imparts heavy smoky qualities to the given whiskey’, That contextual knowledge is derived via the language used to describe certain whiskies in our reviews corpus. Bottom line: It’s fucking cool.
Whoa. Where can I learn more?
Stitchfix’s ‘A Word is Worth a Thousand Vectors’
Chris Olah’s Deep Learning, NLP, and Representations
Tensorflow’s documentation of word2vec
Karpathy’s - The Unreasonable Effectiveness of Recurrent Neural Networks
In fact, if you’re here because you like whiskey and word2vec is entirely new to you, you should definitely look at the first link before you continue, otherwise, nothing here will make sense. Consider it mandatory reading.
You - ‘But I don’t like manditory reading…'
Me - ‘Welp. Bye, Felicia.'
Deeper reading of the topic is provided at the bottom of the page
If you’re familiar with machine learning, but unfamiliar with whiskey
“How we describe the flavors and smells and aromas in whisky? Chocolate, coffee, cognac, wine; is entirely, entirely personal. I come from Scotland, you may not. You grew up in a different place. You eat different food than I do so your nose will tell you things that mine doesn’t and my nose will tell me things that yours doesn’t, so don’t be lead by anyone saying ‘oh you can taste daffodil picked on a west facing slope’, you know, ‘by left-handed people.’’ It doesn’t matter. All you need to do is to work out simple, simple questions: Is it sweet? Yes. How you would describe that sweetness? With the 12 year old, we would describe it with honey, if you were to say white sugar or caramel; it’s the same thing. It’s sweet. If you were to say, the fruit in it, we would describe it as pineapple, if you said fresh green apple or pear, it’s the same thing. It’s a fresh fruit.” - Gerry Tosh, Highland Park link to video
Preach.
Actually, on second thought just watch the whole video: https://youtu.be/HpoIcXfToVs. It’s really simple and really good.
In his 2012 book, ‘The World Atlas of Whisky’, Dave Broom wrote, ‘Whiskey is currently in the same position that wine was 2-years ago: there is a latent desire to try it, but the consumer doesn’t have the language with which to describe what he or she wants. Instead of helping, words have become the barrier.’
Well, Big Davey B, hopefully, a word-embedding approach might be one avenue to break that barrier.
My methodology
For the majority of my experiments, I played with embeddings built from either gensim, chainer, or theano
The Data
This data was scraped via r/bourbon, r/scotch, and r/worldwhiskey. There’s a pretty clean dataset here that I did the majority of the work on: at the Reddit Whisky Review Archive. Thankfully, this dataset had dimensions imposed upon it by some general whisky reviewing standards. For those unfamiliar, it looks something like this where most reviews have a general stream of consiousness type flavor to them:
"""
I'm reviewing the Laphroaig 10 Cask-Strength. I like scotch. Scotchy scotch scotch. Scotch in my belly.
Nose : Powerful smoke and earthy aromas, seaweed. burnt toffee, salty seaweed. pine tree. leather.
Taste : Massive peat smoke, seashore salt, briny wood. peaty smoke. salty tobacco and caramel. vague tartness
Finish : peppery, smoke, long, malt, savory, citrus
Rating : 89/100
Some follow up notes here. Vintage notes if any.
"""
Failed experiments
Initially, I tried to automate the asking of basic questions where a model would return the desired responses. In other words, I tried to naively train a model to figure out that I was asking - ‘what does this whiskey taste like?’ and have it return a summarization of what I wanted to know. The idea slightly inspired by Sukhbaatar et al - arXiv:1503.08895 or keras babi_rnn.py code where the idea was a type of encoder-decoder network that learns to return specific information relating to a given query. The problem, however, was three fold: pure unadulterated laziness (I did not want to build the type of corpus needed to turn this into a supervised learning problem), lack of data (there are only something like 10K clean reviews, each at like 50-100 words per), and the corpus itself. These whiskey reviews are hardly ‘natural language’ the way we consider most text. They’re most often just lists of words that come via stream of consciousness similar to the example review above. Thus, my guess was that the behavior of any question-answer dataset that I would have wanted to build most likely wouldn’t be as well-behaved as the bAbI tasks from this paper: “Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks”
To visualize this phenomenon, take a look at this snake-like TSNE rat-tail created via word2vec’s word vectors. Note: the majority of the words used to describe whiskies occur in the mullet.

Despite its 80’s haircut, similarity queries still produce reasonable responses to the signals of interest in the way we would expect.
In [453]: most_similar('peat')
Out[453]:
[('brine', 0.6719855070114136),
('iodine', 0.6358067989349365),
('campfire', 0.5941624641418457),
('billowing', 0.5907186269760132),
('medicinal', 0.5881044864654541),
('bandages', 0.5756282806396484),
('peatiness', 0.5754231214523315),
('ghostly', 0.5729676485061646),
('salt', 0.5569401979446411),
('funky', 0.5552007555961609)]
In [454]: most_similar('maple')
Out[454]:
[('pancake', 0.8296730518341064),
('corn', 0.8063130378723145),
('cough', 0.7530097365379333),
('molasses', 0.7310086488723755),
('treacle', 0.7281137704849243),
('pecans', 0.721108078956604),
('honeycomb', 0.7178168892860413),
('plump', 0.7121019959449768),
('comb', 0.7095464468002319),
('turkish', 0.7074028849601746)]
In [455]: most_similar('berries')
Out[455]:
[('raspberries', 0.8527774214744568),
('plums', 0.8487773537635803),
('cherries', 0.8433600068092346),
('sultanas', 0.8285631537437439),
('fruits', 0.8216339945793152),
('currants', 0.8172739744186401),
('pomegranate', 0.8159447908401489),
('prunes', 0.8104561567306519),
('strawberries', 0.8091833591461182),
('blackberries', 0.8010640144348145)]
NOTE: For those unfamiliar with word2vec: you might have the desire to disagree with something the algorithm does. For example, say you disagree that the word ‘berries’ is closest to ‘raspberries’ and that ‘blueberries’ or something should be more similar. Don’t worry. Both you, and the algorithm, are not technically wrong, you little precious snowflake.
Given that the vectors seem decent enough to use, here was a super naive implementation of ‘asking a question’. With this code, each ‘sentence’ is now represented by a single n-dimensional array that was the result of the summation of all word-vector representations within that ‘sentence’. This way we can simply use the cosine distance or a basic dot product of our ‘query’ word and that of each sentence representation to find out the ‘closest’ sentence to our given query:
from string import punctuation
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
punctuation = punctuation.replace("'",'').replace('"','')
Trans = str.maketrans(punctuation, ' '*len(punctuation))
# embedding table.
vector_dic = pickle.load(open('vectors.p'))
def review_vectorizer(review):
"""
breaks a review in to sentences of interest.
Params
------
review : str
raw whiskey review
Returns
-------
reconstructed : list(string)
the initial review separated at '\n' lines, cleaned, all
lower case
stack : np.ndarray
len reconstructed X 150. the sentences in vector representation
"""
split_s = [x for x in review.split('\n') if x != '']
cleaned_sentences = list(sentence.lower().translate(Trans).split()
for sentence in split_s)
sentences = []
for sentence in cleaned_sentences:
sentece_vec = [vector_dic[word] for word in sentence]
bag_of_vecs = sum(sentence_vec)
full_sentence = " ".join(sentence)
sentences.append((bag_of_vecs,full_sentence))
reconstructed = [x[1] for x in sentences]
stack = np.vstack([x[0] for x in sentences])
return reconstructed, stack
def query(word, review, vector_dic):
"""
returns the closest part of the review via cosine distance for the word
of interest and the part of the review that is most similar
Params
------
word : str
the word you want to query the sentence for
review : str
raw whiskey review
vector_dic : dict
the vector table built via word2vec
Returns
-------
sentence : str
the sentence with the highest similarity metric to the word of
interest
"""
assert(len(word.split()==1))
reconstructed, stack = review_vectorizer(review)
word_vec = vector_table[word].reshape(1,-1)
test = cosine_similarity(word_vec, stack)
idx = np.argmax(test)
sentence = reconstructed[idx]
return sentence
# this review was for Zuidam Dutch Rye
In [105]: review = """ Rye whisky. 5 years old. 40% ABV.
**color:** Deep copper.
**nose:** Some spice, but it takes a back seat to the sweet and fruity notes. Plenty of vanilla. Baked apples. Candied orange peel. Graham crackers.
**palate:** Smooth and medium-bodied. Orange sherbet and mulling spices.
**finish:** Long but gentle with a cooling menthol sensation.
Score: 86/100
This was one of the more unusual samples I've gotten from Master of Malt. I found it to be familiar yet different. There's a lot less spice than American ryes usually have and there was a creamy, citrus theme going on that I wasn't expecting. Overall I liked it and thought it was interesting but based on the prices I saw online (around $70) a full bottle is out of the question given the abundance of inexpensive rye here at home. Worth tracking down a sample if you're curious.
"""
In [106]: query('taste', review, vector_dic)
Out[106]: 'palate smooth and medium bodied orange sherbet and mulling spices'
In [107]: query('finish', review, vector_dic)
Out[107]: 'finish long but gentle with a cooling menthol sensation'
In [108]: query('smell', review, vector_dic)
Out[108]: 'nose some spice but it takes a back seat to the sweet and fruity notes plenty of vanilla baked apples candied orange peel graham crackers'
Pretty cool. In the case above, it’s almost like an adaptive regex. But here is an example of it failing.
review = """
I'm reviewing the Laphroaig 10 Cask-Strength. I like scotch. Scotchy scotch scotch. Scotch in my belly.
Nose : Powerful smoke and earthy aromas, seaweed. burnt toffee, salty seaweed. pine tree. leather.
Taste : Massive peat smoke, seashore salt, briny wood. peaty smoke. salty tobacco and caramel. vague tartness
Finish : peppery, smoke, long, malt, savory, citrus
Rating : 89/100
Some follow up notes here. Vintage notes if any.
"""
In [112]: query('smell', review, model)
Out[112]: 'taste massive peat smoke seashore salt briny wood peaty smoke salty tobacco and caramel vague tartness'
Despite ‘nose’ and ‘smell’ being interchangeable in the data set, the naive method still fails here. Now, I’m sure you could train a model to attend to certain words. And that would be really cool. But rather than teach AlphaGo over here to figure this out, let’s just be practical and use regex given the lack of variation in the words you’d attending to (e.g., there’s only so many words we care about when breaking this apart: smell - nose, taste - palate, and just plain old finish).
So what the hell am I even trying to do?
Playing with vectors is fun, but let’s see how far we can get with naive bags of vectors representing individual whiskies before we decide to build an Adviserial Glenfarclas Machine. Rein it in, Matt.
Not shown: messing around with stop-word removal led to much better representations of whiskey below. Given that so few words are actually used to describe a given sense dimension, the addition of stopwords just kept throwing off things off; calling most whiskies ‘malty’ on nearly all the dimensions. Not that that’s actually wrong, it’s just not what I was looking for. Also to note, it also made ‘asking questions’ less wrong over a few trials. So if we remove stop-words from reviews and then turn them into dictionaries of flavor profiles, we can pseudo test the bag of vector idea for representing a given whiskey as an n-dimensional array. Thus, the nose dimension for the whisky review above would be: Nose = [powerful vector] + [smoke vector] + [earthy vector] + [aromas vector] + [seaweed vector] + [burnt vector] + [toffee vector] + [salty vector] + [seaweed vector] + [pine vector] + [tree vector] + [leather vector].
For these tests, I just summed nose + taste + finish so that now a whisky is represented by a single 150 dimensional array
#...
# data is a pandas dictionary
# take the names of the whiskies
all_w = list(set(data.whiskey))
vecs = []
for w in all_w:
# data.bag_of_vecs is a array (words X features) for a given whiskey
whiskey_vec = data[data.whiskey == w].bag_of_vecs.values
# take the mean value for the given
whiskey_value = whiskey_vec.mean()
# append to whiskey list
vecs.append(whiskey_value)
# represent whiskies as an array
X = np.vstack(vecs)
# build an index dictionary for X
word_idx = [(i, w) for (i, w) in enumerate(all_w)]
idxdic = {}
wdic = {}
for i, w in word_idx:
idxdic[w] = i
wdic[i] = w
# build a similarity function
def most_similar(whiskey, n=15):
# get index of whiskey so we can get it from X
idx = idxdic[whiskey]
# get cosine distance of given whiskey and all other whiskies
result = cosine_similarity(X[idx].reshape(1,-1), X)
# sort the results.
res_sort = np.argsort(result)
# get the indices, remove the first result
values = res_sort[0][::-1][1:n]
# get the text
most_similar = [wdic[i] for i in values]
return most_similar
For the whiskey drinkers, the results actually look pretty good
In [529]: most_similar('Ardbeg 10')
Out[529]:
['Laphroaig 10 Cask Strength',
'Ardbeg Uigeadail',
'Laphroaig 10',
'Caol Ila 12',
'Lagavulin 16',
'Talisker Storm',
'Lagavulin 12',
'Laphroaig 18',
'Finlaggan Old Reserve',
'Highland Park 12',
'Lagavulin 1997 Distillers Edition',
'Longrow Peated',
'Bowmore 12',
'Laphroaig Quarter Cask']
In [530]: most_similar('Four Roses Single Barrel')
Out[530]:
['W.L. Weller 12',
'Old Weller Antique 107',
'Old Grand Dad 100 Bottled in Bond',
'Knob Creek 9 Small Batch',
"Booker's Bourbon",
"Blanton's Original Single Barrel",
"Maker's Mark",
'Colonel E.H. Taylor Small Batch',
"Russell's Reserve Single Barrel",
'Wild Turkey Rare Breed',
'Elijah Craig Barrel Proof',
'Bulleit Rye',
'Balvenie 14 Caribbean Cask',
'Rock Hill Farms Single Barrel Bourbon']
In [531]: most_similar('Ardbeg Uigeadail')
Out[531]:
['Laphroaig 10 Cask Strength',
'Ardbeg 10',
'Lagavulin 16',
'Lagavulin 1997 Distillers Edition',
'Lagavulin 12',
'Laphroaig 18',
'Highland Park 12',
'Talisker Storm',
'Laphroaig Quarter Cask',
'Laphroaig Cairdeas 2013 Portwood',
'Finlaggan Old Reserve',
'Bunnahabhain 12',
'Bowmore 15 Darkest',
'Caol Ila 12']
For an initial test, and for those unfamiliar, this is pretty damn good. It’s learning the similarity of really peated whiskies and very soft, heavily wheated whiskies.
We’re on to something
For a second test, if we compare each dimension separately, it starts to look a lot more like I would expect. Here, rather than treat each whisky as a single n-dimensional array, we evaluated the cosine distance of each individual whisky on the taste, nose, and finish dimensions separately to that of all other whiskies respective dimensions.
#...
In [497]: most_similar("Ardbeg 10")
Out[497]:
[('Laphroaig 10', 0.98225728690624237),
('Highland Park 12', 0.98141257464885712),
('Caol Ila 12', 0.98074275016784673),
('Talisker Storm', 0.98014752328395849),
('Lagavulin 16', 0.97319974303245549),
('Kilchoman Machir Bay', 0.97103935480117798),
('Bunnahabhain 12', 0.96981545805931091),
('Ardbeg Uigeadail', 0.96897226393222802),
('Laphroaig 18', 0.96870719194412236),
('Laphroaig Quarter Cask', 0.9685075163841248),
('Talisker 10', 0.96826540708541864),
('Lagavulin 12', 0.9676340079307556),
('Laphroaig 10 Cask Strength', 0.96573835432529442),
('Talisker 57° North', 0.96473644196987152),
('Ledaig 10', 0.96473363816738122)]
In [498]: most_similar("Four Roses Single Barrel")
Out[498]:
[('W.L. Weller 12', 0.98039752006530767),
('Old Weller Antique 107', 0.97847300052642816),
('Old Grand Dad 114', 0.97778435051441193),
('Old Grand Dad 100 Bottled in Bond', 0.97584160685539245),
('Elmer T. Lee', 0.97437110304832464),
('Colonel E.H. Taylor Small Batch', 0.97433447599411016),
("Blanton's Original Single Barrel", 0.97375291109085083),
('Wild Turkey Rare Breed', 0.97322319209575658),
('Balvenie 14 Caribbean Cask', 0.97262043297290801),
('Knob Creek 9 Small Batch', 0.97231273889541625),
('Glenmorangie Astar', 0.97189790010452271),
("Russell's Reserve Single Barrel", 0.97158373415470123),
('Elijah Craig Barrel Proof', 0.97119110345840454),
('Bulleit Rye', 0.96869591414928435),
('Glenlivet 16 Nadurra', 0.96857591748237604)]
In [499]: most_similar("Ardbeg Uigeadail")
Out[499]:
[('Lagavulin 16', 0.98130033433437347),
('Lagavulin 12', 0.98006941139698034),
('Laphroaig 10 Cask Strength', 0.97966188192367554),
('Laphroaig Quarter Cask', 0.97405486822128295),
('Laphroaig 18', 0.97076774656772613),
('Ardbeg 10', 0.96897226393222802),
('Lagavulin 1997 Distillers Edition', 0.9665562635660172),
('Talisker 10', 0.9664697104692459),
('Laphroaig 10', 0.96640086472034459),
('Laphroaig Cairdeas 2013 Portwood', 0.96637647867202758),
('Ardbeg Ardbog', 0.96615850448608398),
('Ardbeg Corryvreckan', 0.96584754943847662),
('Highland Park 12', 0.96557600617408745),
('Springbank 12 Cask Strength', 0.96336297214031219),
('Ardbeg Galileo', 0.96185846149921417)]
With the distances visualized, you can see that they’re all so very close. And yet, this fairly naive model does a really good job at evaluating the small subtleties that we whiskey drinkers can detect in our hooch. What’s pretty cool is that if someone was really into Four Roses, and you said: ‘try the Glenmorangie Astar’, they’d probably like it.
Cherry picking here on some data not in the dataset used: This is a Glenmorangie Astar review from The Whiskey Exchange that literally calls it ‘bourbony’
"""
Nose: Ginger, citrus, tweed, paprika, black pepper, becomes very deep with smoky vanilla. Maybe it's the power of suggestion, but the oak is very noticeable - polished wood, like an expensive bookcase. More masculine and intense than the old Artisan, but you'd expect that from the higher abv. Water opens up more sweet notes, natural caramel or butter toffee.
Palate: Carries on from the nose. Big, assertive and very bourbony. Exceptionally spicy and peppery but with compensating sweet creamy vanilla. Big mouth-filling weight - quite macho. With water, much more approachable though still very spicy
Finish: Immense. Very long and warming, with tingling spices that last an eon. My mouth was still burning (in a good way) several minutes after the swallow.
Comment: If you're a committed sherryhead or you don't like oaky stuff or spicy food - avoid. Everyone else will love it. Very much of the same breed as the original Artisan cask, but less gentle - much more powerful and concentrated. An epic dram that needs a drop or two of water to really shine.
"""
So validating this model via this whiskey drinker gut-feeling seems to work out pretty well here. Pretty cool we got to this spot with just bags of vectors and simple cosine distances.So if we think these vectors are at least half-way decent at this point, and validating their integrity with regard to representing whiskies has been done, let’s start to make some brash generalizations and make people angry.
If we represent a given whiskey’s taste-profile as an array consisting of all taste profiles (eg, reviews) for that given whiskey where each individual taste profile is represented as the vector sum of that taste profile, we can start to generalize about a given whiskey accross many different reviews. That array would look something like this (# of reviews x 150-dimensions). We can take the mean of that array to represent the given whiskey’s ‘taste-centroid’. When we take the ‘taste centroid’ and do the cosine distance of the centroid to that of all other words in the vector dictionary, we can return the N closests words for that given centroid. And when we do this for taste, smell, and finish, we can make generalizations about a given whiskey across many reviews.
#...
sorted_words = sorted(list(model.keys()))
vectors = np.vstack(model[word] for word in sorted_words)
def return_means(x,df):
# get data from dataframe
data = df[df.whiskey == x]
#vectorize all words in each part of the review
nose = [model[word] for word in data.nose]
palate = [model[word] for word in data.palate]
finish = [model[word] for word in data.finish]
# get means from each sense-dimension
mean_nose = np.vstack(nose).mean(axis=0)
mean_palate = np.vstack(palate).mean(axis=0)
mean_finish = np.vstack(finish).mean(axis=0)
return mean_nose, mean_taste, mean_finish
def return_dimension_generalization(mean):
words = list(model.vocab.keys())
vectors = np.vstack(model[word] for word in words)
dists = np.dot(vectors, mean)
return sorted(zip(dists, words))[::-1]
In [500]: mean_nose, mean_taste, mean_finish = return_means('Ardbeg 10',data)
In [501]: return_dimension_generalization(mean_nose)[:100]
Out [499]:
['brine,', 'iodine,', 'smoked,', 'meat,', 'salt,', 'seaweed,', 'ash,', 'tar,', 'grass,', 'fennel,', 'lime,', 'pepper,', 'shavings,', 'char,', 'lemon,', 'bacon,', 'sea,', 'hay,', 'melon,', 'salted,', 'paprika,', 'zest,', 'hint,', 'meats,', 'hazelnuts,', 'campfire,', 'charcoal,', 'spray,', 'clover,', 'breeze,', 'wet,', 'herbs,', 'pine,', 'smoke,', 'toffee,', 'peel,', 'pineapple,', 'leather,', 'licorice,', 'anise,', 'citrus,', 'pork,', 'walnuts,', 'olive,', 'allspice,', 'polish,', 'taffy,', 'rubber,', 'pith,', 'clove,', 'vegetal,', 'ginger,', 'salty,', 'almonds,', 'liquorice,', 'soil,', 'faint,', 'carmel,', 'cedar,', 'mint,', 'tobacco,', 'damp,', 'honeydew,', 'buttered,', 'bananas,', 'seed,', 'slight,', 'medicinal,', 'peaches,', 'cloves,', 'rind,', 'oranges,', 'custard,', 'cardamom,', 'charred,', 'graham,', 'sugar,', 'cinnamon,', 'butter,', 'vanilla,', 'marzipan,', 'menthol,', 'maple,', 'caramel,', 'figs,', 'cola,', 'coriander,', 'overripe,', 'crust,', 'cured,', 'almond,', 'aniseed,', 'sauce,', 'cumin,', 'earthy,', 'powder,', 'dates,', 'grapefruit,', 'nutmeg,', 'air']
Holy shit. That looks good. Better do a super biased 1-man whiskey drinking experiment just to be sure. For science.
Obligatory Rat-tail visualization. Colors indicate which sense dimension the given word occurs in:

Final touches
When considering ‘average scores’, I tend to side with a prior belief that with smaller datasets like this, the average should be a bit closer to the median rather than a standard average. Also pushing me towards that belief, newer reviewers tend to rate more on hype and rather than letting reviews like ‘This Pappy from 2014 that I had on the rocks was a 99/100’ skew the review pools, I wanted a Bayesian function that uses a prior a bit closer to the median so as to avoid any weirdness.
# Some final touches.
# overall mean
In [141]: ratings.mean()
Out[141]: 83.70441842086358
In [142]: %paste
def bayesian_mean(arr, confidence=95):
"""
Computes the Bayesian mean from the median prior and confidence.
weights mean towards prior
Parameters
----------
arr : pandas.DataFrame
array you want to compute the bayesian mean on
"""
return (confidence * arr.median() + arr.sum()) / (confidence + arr.count())
## -- End pasted text --
In [143]: bayesian_mean(ratings)
Out[143]: 83.719980019980028
In [144]: pappy = df[df.whiskey.str.contains('Pappy Van Winkle Family Reserve Bourbon 23')]
In [145]: pappy.shape
Out[145]: (4, 9)
In [146]: pappy.Rating.mean()
Out[146]: 92.0
In [147]: bayesian_mean(pappy.Rating)
Out[147]: 92.969387755102048
With regard to the Pappy reviews, here’s a perfect example of the prior weighting saying: “Yeah, the price is definitely not worth it, but it’s probably a smidge better than you’re giving it credit for”. In the end, does the median prior really matter? Nope..
Points to note
PSA: For non-whiskey drinking machine learning people, the curious, or the rather new whiskey drinkers
With regard to the above fictitious review: “This Pappy from 2014 that I had on the rocks was 99/100." I’m not going to tell you how to enjoy your whiskey. But it’s a fact that cold temperatures inhibit flavor. Whiskey is no different. Data here –> Heat activation of TRPM5 underlies thermal sensitivity of sweet taste, TRPM5 and Taste Transduction, TRPM5 - Wikipedia. Science is pretty cool, and if you say fuck it, you’ve drank enough whiskey in your day to know that you enjoy muted flavors, by all means, fill that glass up with ice and pour away. It’s a two way street, as well. That whiskey tastes like garbage? Put some ice in it. It will make its trash flavors less noticeable.
Some obligatory whiskey links: check out the main event himself, Mr. Ralfy at - Ralfy’s whiskey reviews. Also, check out r/bourbon, r/scotch, and r/worldwhiskey
End PSA
Where next?
One attempt that I forgot to include was using a Variational Autoencoder to learn the ‘true essence’ of a given whiskey. The results were pretty cool and I’ll have to include them in another post.
With regard to this model, a real downfall is that it does not address batch variation, in part because rarely do whiskey reviews in the dataset contain the bottling vintage. However, based on recent reviews (2016), more reviewers are adding the vintage to the review and that’s a good thing for every consumer. Hopefully I can tackle this in the future when I have some free time.
This dataset also made the assumption that the Reddit Review Archive has every name standardized - it definitely doesn’t. I hope to address that when I get some free time as well. It also is a really rough first pass - I’m not winning any design awards.
I’m currently working on an area of interest that combines my love a whiskey and my love of computer vision: OCR on curved text. With the goal being that I can take a picture of a bottle and an algorithm can return the given profile dimensions. Normally, I’d just amass training data for whiskey bottles and then classify them via some type of VGG offshoot. But the immediate problem is that whiskey labels change all the time. Combine that with all the independent bottlings that a given algorithm would never see in it’s training data and we’re be in for a real problem. Plain and simple: we need to teach the fucker how to read then just let it do it’s thing. Some possible solutions are from papers using deep architectures trying to solve text recognition in the wild: Reading Text in the Wild with Convolutional Neural Networks and Deep Features for Text Spotting. My initial tests have them failing with bottles and other texts that are non-linear. Perhaps something like Alignment of Curved Text Strings for Enhanced OCR Readability might be beneficial. Truth be told, however, I’d rather have a network learn what curved data looks like in an end-to-end fashion rather than correct for it. Perhaps some non-linear pixel RNN ensemble? Who knows. Not sure what the outcome will be, but it will be awesome to play around with.
Lastly, Like most of these problems, they suffer from a lack of data, and hopefully my small ‘bottle text dataset’ might come in handy down the road. It’s a work in progress, but I’ll release it when I get there eventually.
Making a good whiskey is hard. Thankfully, finding one you might like is easy.